Webseiten-Analyse



Onsite Analyse
Interne Verlinkung

Onpage-Analyse
Einmalig
€
auf Anfrage
Hier werden Themen des technischen SEO's und der Inhaltsoptimierung durchleuchtet. Das Konzept umfasst ca. 40 Seiten und deckt alle relevanten Faktoren der Suchmaschinenoptimierung ab.
- URL-Design
- Zugriffssteuerung
- Ladezeit
- Meta-Angaben
- Überschriften
- Inhaltsrelevanz (Terme, WDF*IDF)
- Strukturierte Daten
- Duplicate und Thin-Content
- Weitere Faktoren ...
Konzept Interne Verlinkung
Einmalig
€
auf Anfrage
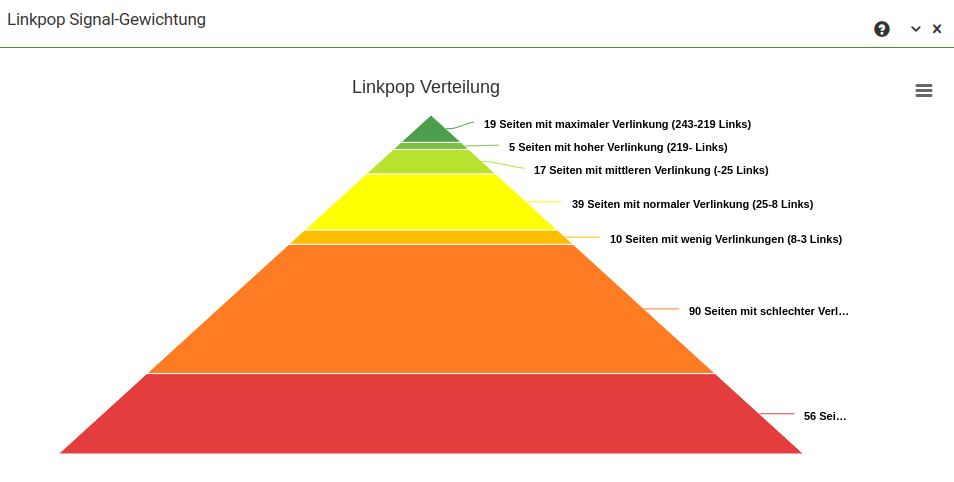
Die interne Verlinkung ist einer der größten Hebel. Wir zeigen Ihnen wie Sie die Struktur Ihrer Webseite verbessern können. Neben den globalen Faktoren gehen wir detailiert auf Seitenebene ein, welche Maßnahmen umzusetzen sind. Das Konzept umfasst in der Regel 60-80 Seiten.
Analysiert werden:
- Hirachien und Webseitenstruktur
- Indexierungsregeln
- Linkjuice Verteilung
- Keyword-Targeting
- Gewichtung und Ausrichtung
- Hebel in der Optimierung
- Maßnahmen auf Start, Kategorie und Produktseiten
SEO Beratung
Nach Aufwand
€
120
Um das Team für alle wichtigen Themenbereiche der Suchmaschinenoptimierung zu unterstützen, stehen wir Ihnen gerne zur Verfügung.
Unsere SEO-Beratung bietet:
- Email Support bei Fragen
- Entwickeln von neuen Ideen
- Permanente Betreuung in Hinblick auf Algorithmus-Änderungen, Entwicklungen und Trends
- Monatliche Telko zum Projektmanament und Controlling
- etc.